
Misskey Advent Calendar 2024
この記事は、Misskeyアドベントカレンダー2024に際して作成しました!
去年に引き続き今年も参加できて、とても嬉しいです。ありがとうございます!
Misskey Advent Calendar 2024 - Adventar
はじめに
SNSをはじめとしたコミュニケーションツールの普及は、我々の生活の利便性を大きく向上させるとともに、ストレスの大きな原因となっています。
しかしながら、現代社会において、これらのコミュニケーションツールを使用せずに生きていくことは、もはや不可能です。この記事を見ている人の多くがSNSにハマっている人でしょうから、なおさらだと思います。私もです。
そこで、我々に必要なものは「癒やし」であると考えます。このSNS上にも何らかの癒やし要素があれば、ストレスを低減させながらコミュニケーションを楽しむことができるでしょう。
そして私は考えました。あなたの話をいつでも聞いてくれて、いつでも何気ない会話ができる。そんなお友達がSNS上にいてくれたなら、どれだけ癒やしに繋がることか。
……という大袈裟なお芝居はこのへんにして、なんとなく日常会話ができるようなMisskey botを、流行りのLLMを使って作りたいなあと思い立ちました。
記事作成時点では、メンションして話しかけるとリプライをしてくれて、リプライを送り合うと会話を続けられるようなところまでは完成しています。筆者が自分用のMisskeyインスタンスとして管理している Momogumi で稼働させています。稼働?いいえ、活動してもらっています。皆さんの住んでいるインスタンスでフォローしてあげてください。@[email protected]です。
この記事では、LLMとかAIがどんな感じで動いていて、それをMisskeyでどう使っているんだー的なことがなんとなく理解できることを目的としています。したがって、記事内では技術的なアレコレとか具体的なコードとかは控えめにしています。ちょっと調べればすぐ出てきますしね。
あっ、最初に書いておきますが、筆者はLLMに関して全くの無知の状態から作成し記事を書いているので、記事内で書いていることが変だったりコードが稚拙だったりするかもしれません!ご了承ください。
LLMとは?
大規模言語モデル(Large Language Model; LLM)は、インターネット上などから収集した膨大なテキストデータを学習させた、テキスト生成のための深層学習モデルです。
LLMの基本的な仕組みとして、「入力された文字列から続くであろうもっともらしい文字列を生成する」ものらしいです。
最近のLLMでよく用いられているTransformerというモデルが、連続するデータを読み解いて未知のデータを予測するような仕組みのようです。なんかこっちが投げた質問にいい感じに答えてくれるように訓練されたものだと思っていましたが、必ずしもそういうわけではないみたい。
LLMをローカルで動かすには?
早速ですが、LLMをローカル環境(おうちのPC)で動かす環境を作っていきます。
ハードウェア
LLMをローカルのPCで動かすには、それなりにVRAM容量の大きいNVIDIAのGPUが必要です。
筆者の家にはNVIDIAのGTX 1080 Tiというメモリが11GBくらいあるグラフィックボードがあったので、これを使います。
(まてかすのメモ帳では、皆様のご家庭でご不要となったグラフィックボードを無償で回収いたします。ぜひお声がけください。)

ソフトウェア
PCでLLMを動かすためのソフトウェアはいくつかありますが、今回はllama.cppを使います。
llama.cppを使用する理由としては、後述する量子化モデルを扱いやすい点と、Pythonで扱いやすい点が挙げられます。
llama.cppをPythonで使用するためのライブラリとしてllama-cpp-pythonが提供されており、Misskey Botに統合する上で都合が良いです。
abetlen/llama-cpp-python: Python bindings for llama.cpp
モデルを選ぶ
LLMは Hugging Face などでたくさん公開されています。一から作ったものもあれば、他のモデルに追加学習したりモデル同士をマージしたりしたようなものもあります。
とりあえずHugging Faceのモデル検索ページを開いて、TasksをText Generation、LanguagesをJapaneseにして検索します。
前述の通り、筆者はLLMに関する知見が一切無かったので、どうやってモデルを選んでいいのか全くわかりませんでした。
どうやら、GGUFとついているものがLlama.cppで使うように量子化されているモデル?らしいです。
今回使用するモデル(本記事の作成時に使用しているモデル)はこちらです。このモデルをGGUF形式に変換したものです。
ReadyON/Berghof-ERP-7B-gguf · Hugging Face
採用理由は以下のとおりです。
- 与えたキャラクターを守りチャット用途に調整されている
- NSFWな文字列を生成できる(!?)
量子化って何だよ
未だによくわかっていませんが、モデルのサイズを節約するための技術らしいです。
LLMに限らず深層学習モデルは無数の小数のパラメータによって構成されています。コンピュータで小数を扱うときは浮動小数というフォーマットを用いますが、その小数の表現の精度を下げてもそこまでモデルの性能に影響が出ないことがわかっているようです。
サイズの大きいモデルは、一般家庭にあるようなグラフィックボードのGPUメモリ上に乗り切らないので、量子化によって性能を保ちながらモデルサイズを節約するみたいです。
LLMと会話するには?
以下のノートは、過去にGoogleがGemini(当時はBardだったっけ)のAPIを無料で提供していたときに雑に作ったMisskey botの返信です。
ChatGPTのように、アシスタントらしい “真面目な” 受け答えを行うbotは簡単に作れるのですが、今回作りたいのはこういうものではありません。いや、真面目な口調で変なことを言うbotも面白くはあるんですが、もっと日常的な会話ができて “かわいい” botを作りたいのです。
自然に会話したい
では、LLMと自然な会話を試みたいと思います。
先述の通り、LLMは「入力された文字列から続くであろうもっともらしい文字列を生成する」仕組みです。
この仕組みを利用するならば、「仲の良さそうな2人が自然に会話しているテキスト」を投げて続きを生成してもらえばよさそうです。
例えば、具体的には以下のようなテキストを投げます。
A「今日もいい天気ね」
B「そうだね」
A「今日はどこに行こうかしら」
B「
上のテキストはAとBの会話を示したものですが、Bの発言が「で止まっています。
もし私がLLMであれば、このテキストから続くもっともらしい文字列といったら以下のようになるかなと思います。
A「今日もいい天気ね」
B「そうだね」
A「今日はどこに行こうかしら」
B「公園にでも行こうよ」
A「いいね、公園を散歩をしたら、きっと気持ちがいいわ」
B「それじゃあ早速準備をしなくちゃね」
……
公園にでも行こうよ」のように、Aの発言に回答しつつ、」で終了するようなテキストが生成されるはずです。
「で終わるテキストの続きを生成させたら、その後に(ほぼ)必ず」が来ることが予想できるので、」で出力を止めちゃうようにすればいいですね。
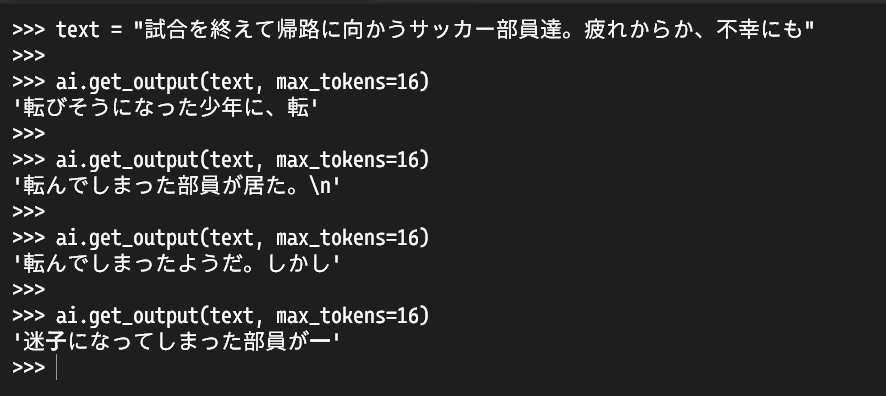
実際に投げてみると、以下のように、Bが次に喋りそうな内容を出力することができています。

LLMにキャラクターをもたせる
今の状態ではLLMが生成するテキストにキャラクター性を持たせられていません。キャラクターが無いというよりは、キャラクターが安定していないと表現するほうが正しいかもしれません。
こちらが投げるテキストにそれっぽい返事を返しているだけなので、話しかけ方によって全然違う人から返事が来てしまいます。

そこで、性格を固定するために、LLMに入力するテキストを以下のように設定します。
ももの名前は 青天目もも(なばため もも)!
小学校5年生だよ!
趣味は本を読むこととゲームかな~
特技は誰とでも話せることかな!みんな大好き!
勉強は、うーん、勉強の話はやめよっか、えへへ~
べ、別に苦手ってわけじゃないからね……!
もも、今日も学校があってね、友達とこんな話をしてたんだよ!
---------
まてちゃん「ももちゃん、おはよー」
もも「
ここで設定した会話のテキストの前に、どのようなキャラクターと会話したいか背景情報のようなものを追加します。
このとき、そのキャラクターが自己紹介をするような感じのテキストだとよいです。キャラクターの口調などを再現してくれるようになる気がします。
上の例を実際に投げて、会話を生成させます。すると、こちらの発言に対して子供らしく回答してくれています。


LLMとMisskeyをつなげる
LLMで会話をすることが可能となったので、LLMとMisskeyを繋げていきます。
(ここまでが長すぎる、本当にMisskeyアドカレ記事か?)
今回の記事では、以下のノートのツリーのように、ユーザがメンションやリプライをするとテキストを返してくれるbotを作るところまで取り組みたいと思います。
Misskey botフレームワーク MiPA
Misskey botを作る際に、多くの場合は何らかのプログラミング言語を使用することになると思います。特に機械学習系のライブラリは、今回使用するllama-cpp-pythonも含めてPython用のものが多いです。よって、Misskey用のコード(ノートやユーザの情報を取得して処理するなど)もPythonで書けると楽です。
そこで、Python用のMisskey botフレームワークである MiPA を使用します。
機械学習系のライブラリを使用するMisskey botを作る場合(普通そんなことある?)は、PythonとMiPAを使うのがベストな気がします。おすすめです。
ノートの情報からLLMに対する入力を生成する
MisskeyのAPIを使用すると、ノートの情報をデータとして取得できます。例えば、プロフィールで設定できる名前name、ノート本文text、どのノートにリプライをしたかを表すreplyId、誰をメンションしたかを表すmentionsなどです。これらの情報を使ってLLMへの入力を生成します。
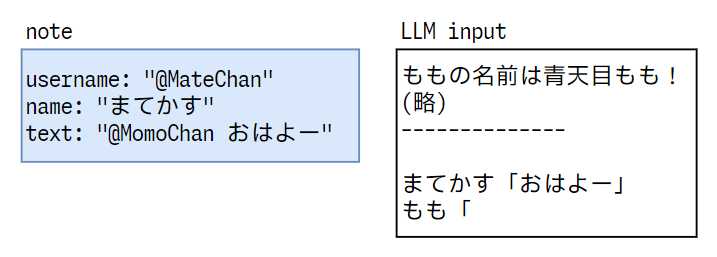
文字列のフォーマットやnullへの対応など、いくつかの処理を挟みますが、基本的には "{name}「{text}」" の型で文字列を生成します。
{name}「{text}」の前にbotの自己紹介文、末尾に〇〇「を追加して、これをLLMへの入力とします。
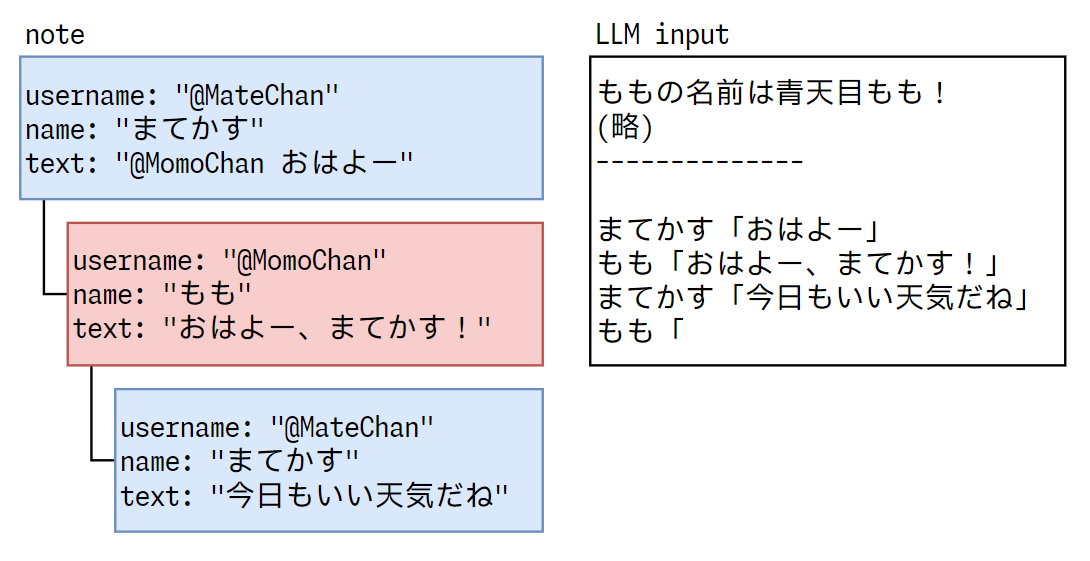
ユーザとbotがリプライを送り合って会話をすると、そのノートはツリー構造を成します。一つのノートから一つの{name}「{text}」を生成するので、リプライを送り合うとその分だけ{name}「{text}」が増えることになりますが、基本的な方法は同じです。
ユーザごとにニックネームを考える
みんなが「まてかす」みたいにシンプルでわかりやすい名前をしていればいいですが、SNSには複雑なニックネームを設定しているユーザがたくさんいます。あまりにも複雑なニックネームだと、LLMに入力するテキストを生成する段階で困ってしまうので、ユーザそれぞれにニックネームを考えます。考えるのはもちろんLLMです。
ニックネームを考えてもらうには、先述した会話の生成を応用し、以下のようなテキストをLLMに入力します。
ももの名前は 青天目もも(なばため もも)!
小学校5年生だよ!
趣味は本を読むこととゲームかな~
特技は誰とでも話せることかな!みんな大好き!
勉強は、うーん、勉強の話はやめよっか、えへへ~
べ、別に苦手ってわけじゃないからね……!
もも、今日も学校があってね、友達とこんな話をしてたんだよ!
---------
まてかす「あ、もも!ちょうどいいところに」
もも「まてかすちゃん、どうかしたの?」
まてかす「ネットでね、「{name}」って名前の子がいるんだけど、なんて呼んであげるのがいいかなあ」
もも「うーん、ももだったら『
ももちゃんの自己紹介の部分は前のままですね。
ニックネームを考えてもらいたいので、誰かのニックネームを考えている2人の会話を生成させます。{name}の部分には各ユーザが設定している名前またはユーザネームが入ります。上のテキストは『で途切れているので、』で生成を終了するようにすれば、考えてもらったニックネーム部分だけを取り出せます。
呼び方が毎回変わるのはよくないので、考えたニックネームはユーザのidと紐づけて保存しておきます。
botを実際に動かす
LLMをbotとして動かすために必要な内容は、一通りこんなもので以上だと思います。
では実際におしゃべりをしていきます。
最初は軽く挨拶をします。
「まてかす」という名前から「まてちゃん」というニックネームを考えて呼んでいることがわかります。
では次に、好きな食べ物でも聞いてみましょうか。
ママの作ったハンバーグが好きみたいです。モモチャンカワイイヤッター
キャラクターの設定のところで小学5年生を指示しているので、子供らしい部分がちゃんと表現できていますね。
好きな食べ物についてこちらから設定を指示していないので、聞くたびに違う答えが返ってきます。一貫性を持たせたい設定などがある場合は、こちらからちゃんと指示してあげたほうがいいかも。
とまあ、こんな感じで、当初の目的であった「なんとなく日常会話ができるbot」を作ることに成功しました。めでたしめでたし。
おわりに
今後の展望として、よく話しかけてくれる人に対して好感度を上げるシステムや、過去の会話の内容を覚えておくシステムなどを実装したいと思っております。また、タイムライン上のコンテキストを読み取って自発的におしゃべりするようなところまでできたら、かなり面白そうだなあと思っています。
ぜひ、みなさんが住んでいるインスタンスで @[email protected] をフォローして、たくさん話しかけてあげてくださいね。
以上です。